
Building a rule engine in c# (part 8: extending the rule engine with method calls of the objects)
Posted: 07/07/2015 Filed under: .net 19 CommentsIn a comment on a blog article (https://netmatze.wordpress.com/2014/09/17/building-a-rule-engine-in-c-part-7-extending-the-rule-engine-with-a-like-operator/) about the rule engine project (ruleengine.codeplex.com) Matt wrote that he would need the feature that the makes it possible to call methodes at the object and check for the result of that method calls. So i made some changes to the rule engine project to make that possible. I released a new version at codeplex and here you can see a test that uses that method calls.
[TestMethod] public void SimpleExpressionEvaluatorWasEmployedDateMethod() { Person person1 = new Person() { Name = "Mathias", Age = 36, Children = 2, Married = true, Birthdate = new DateTime(1976, 5, 9), EmployDate = new DateTime(2012,12,1) }; Person person2 = new Person() { Name = "Anna", Age = 32, Children = 2, Married = false, Birthdate = new DateTime(2002, 2, 2), EmployDate = new DateTime(2013, 12, 1) }; Person person3 = new Person() { Name = "Karo", Age = 38, Children = 2, Married = true, Birthdate = new DateTime(1976, 2, 2), EmployDate = new DateTime(2011, 12, 1) }; Evaluator evaluator = new Evaluator(); var result1 = evaluator.Evaluate(" (CalculateAge() >= 10 && Married = true) && WasEmployed('2013-12-01') = true ", person1); Assert.AreEqual(result1, true); var result2 = evaluator.Evaluate(" CalculateAge() >= 10 && Married = true || WasEmployed('2014-12-01') = false ", person2); Assert.AreEqual(result2, false); var result3 = evaluator.Evaluate( " (CalculateAge() >= 2 || Married = true || WasEmployed('2010-12-01') = true) then SetCanReceiveBenefits(true) else SetCancelBenefits(true) ", person3); Assert.AreEqual(result3, true); Assert.AreEqual(person3.CancelBenefits, false); Assert.AreEqual(person3.ReceiveBenefits, true); }
Using ExtendedFileInfo Project to avoid a System.IO.PathTooLongException.
Posted: 26/12/2014 Filed under: .net, c#, ExtendedFileInfo | Tags: .net, c#, ExtendedFileInfo 2 CommentsThe ExtendedFileInfo Project is a libary that you can use if you have path information longer than 248 chars and file and path information longer than 260 chars. When you search for a solution to the
System.IO.PathTooLongException: “The specified path, file name, or both are too long. The fully qualified file name must be less than 260 characters, and the directory name must be less than 248 characters.”
the ExtendedFileInfo is what you are searching for. I had the problem at a project where the path where xml configuration files where saved and the name of the xml file exceeded 260 chars. The use of that files where covered over the whole project so i had to find a global solution that uses no FileInfo class if the path and the filename where longer as 260 chars. To accomplish that i implemented the ExtendetFileInfo library and i put it to codeplex. It works the following way, if i access a file the library checks the path and if the path is too long it uses the windows api functions to access the file an no PathTooLongException is thrown. I implemented a IFileInfo interface that is used to hide the calls to the windows api or to a FileInfo object.
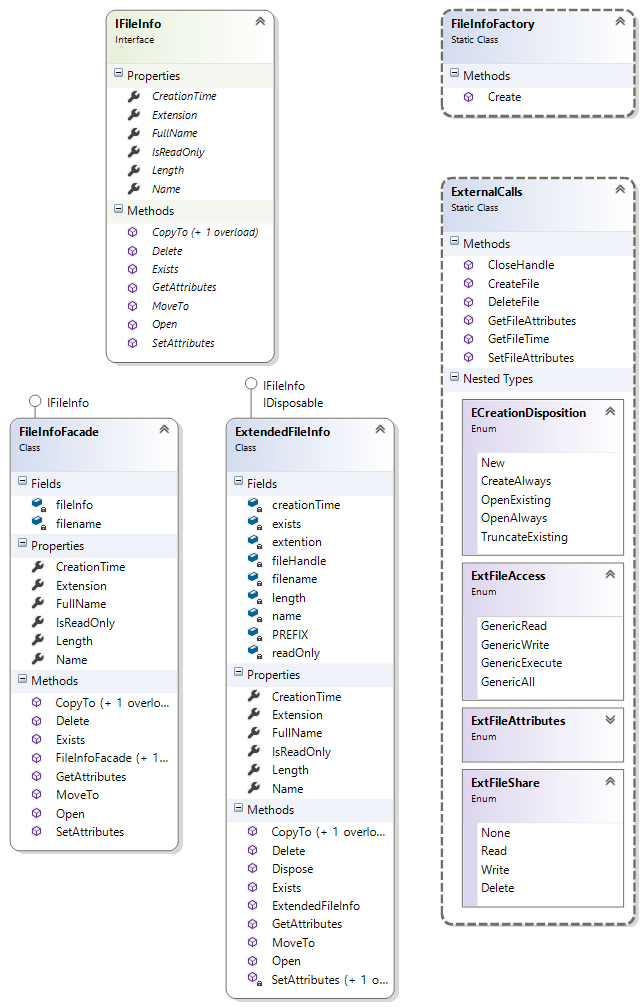
ExtendedFileInfo class diagram
Here you see a test call that uses a short and a long path to a specific file:
[TestClass] public class ExtendedFileInfoTest { [TestMethod] public void ExtendedFileInfoTestShortFilePath() { var shortFilePath = @"C:\FilePath\ShortPath\Textdocument.txt"; var extendedFileInfo = FileInfoFactory.Create(shortFilePath); using(var fileStream = extendedFileInfo.Open(FileMode.Open, FileAccess.Read)) { var buffer = new byte[fileStream.Length]; fileStream.Read(buffer, 0, buffer.Length); } } [TestMethod] public void ExtendedFileInfoTestLongFilePath() { var longFilePath = @"C:\FilePath\" + @"Looooooooooooooooooooooooooooooooooooooooooooooooooooooooo" + @"oooooooooooooooooooooooooooooooooooooooooooooooooPath\" + @"Looooooooooooooooooooooooooooooooooooooooooooooooooooo" + @"ooooooooooooooooooooooooooooooooooooooooooooooooooooog\" + "Textdocument.txt"; var extendedFileInfo = FileInfoFactory.Create(longFilePath); using (var fileStream = extendedFileInfo.Open(FileMode.Open, FileAccess.Read)) { var buffer = new byte[fileStream.Length]; fileStream.Read(buffer, 0, buffer.Length); } } }
Extended IFileInfo interface has the following methodes and properties:
public interface IFileInfo { bool Exists(); bool IsReadOnly { get; } long Length { get; } string Name { get; } FileStream Open(FileMode fileMode, FileAccess fileAccess); IFileInfo CopyTo(string destFileName); IFileInfo CopyTo(string destFileName, bool overwrite); void MoveTo(string destFileName); void Delete(); void SetAttributes(FileAttributes fileAttributes); FileAttributes GetAttributes(); DateTime CreationTime { get; } string Extension { get; } string FullName { get; } }
That means you can use all that methodes and properties like you would use it with a .net FileInfo object. So when i had that problem in my project it took me a lot of time to find the correct winapi calls and use them the correct way. So i thought if someone has the same problem it would be nice to just include a dll and the call to the FileInfo object works again.
Implementing a sychronized priority queue in c#
Posted: 17/09/2014 Filed under: .net, Algorithm, c#, concurrency, Data Structures | Tags: c#, data structure, list, priority queue, synchronized Leave a commentAt my last project i used a queue to add download and upload tasks of documents. After most of the implementation was done i discovered that some of the upload and download tasks should have higher priority than others. So for my implementation i used a synchnoized wrapper of the .net queue. And with a queue it is not possible to work with items that have different priorities. At the following picture the use of a queue is ilustrated.

So at that point i was looking for a priority queue. The problem is that the .net framework does not provide such a data structure, so i had to implement it myself. The following picture shows how a priority queue works.

So if you want to implement a priority queue you need an underlying data structure. That data structure has to reorganize the enqued items so that the item with the highest priority is dequeued first. So one possible data structure is a list you reorder. If a item with a higher priority is enqued you bring it to the front of the list. That works fine with hundred of added items. But if you have several thousend items to enqueue the solution with the list gets slower and slower. Then you need a priority queue that is implemented with a tree structure. You could use a balanced search tree like an AVL tree, but most of data structure books recomend a binary heap. So i decided to implement my priority queue with two modes. In one mode it internaly uses a list, in the second mode it uses a binary heap. If you want to look at the code or use the priority queue, i added it to codeplex. (http://priorityQueue.codeplex.com).
Here is the uml class diagram and a two tests that show the use of the priority queue in linked list and in binary heap mode.

[TestClass] public class PriorityQueueTests { [TestMethod] public void PriorityQueueListModeTest() { PriorityQueue<int, string> priorityQueue = new PriorityQueue<int, string>(PriorityQueueMode.LinkedList); priorityQueue.Enqueue(1, "A"); priorityQueue.Enqueue(2, "B"); priorityQueue.Enqueue(3, "C"); priorityQueue.Enqueue(4, "D"); priorityQueue.Enqueue(5, "E"); priorityQueue.Enqueue(6, "F"); var count = priorityQueue.Count; var result = priorityQueue.Dequeue(); Assert.AreEqual(result, "F"); result = priorityQueue.Dequeue(); Assert.AreEqual(result, "E"); result = priorityQueue.Dequeue(); Assert.AreEqual(result, "D"); result = priorityQueue.Dequeue(); Assert.AreEqual(result, "C"); result = priorityQueue.Dequeue(); Assert.AreEqual(result, "B"); result = priorityQueue.Dequeue(); Assert.AreEqual(result, "A"); } [TestMethod] public void PriorityQueueBinaryHeapModeTest() { PriorityQueue<int, string> priorityQueue = new PriorityQueue<int, string>(PriorityQueueMode.BinaryHeap); priorityQueue.Enqueue(1, "A"); priorityQueue.Enqueue(2, "B"); priorityQueue.Enqueue(3, "C"); priorityQueue.Enqueue(4, "D"); priorityQueue.Enqueue(5, "E"); priorityQueue.Enqueue(6, "F"); var count = priorityQueue.Count; var result = priorityQueue.Dequeue(); Assert.AreEqual(result, "F"); result = priorityQueue.Dequeue(); Assert.AreEqual(result, "E"); result = priorityQueue.Dequeue(); Assert.AreEqual(result, "D"); result = priorityQueue.Dequeue(); Assert.AreEqual(result, "C"); result = priorityQueue.Dequeue(); Assert.AreEqual(result, "B"); result = priorityQueue.Dequeue(); Assert.AreEqual(result, "A"); } }
The two tests show that the items with higher priority are ranked at the top of the priority queue and the items with lower priority are ranked at the end of the priority queue.
Building a rule engine in c# (part 7: extending the rule engine with a like operator)
Posted: 17/09/2014 Filed under: .net, c#, Parser, rule engine | Tags: .net, c#, like, operator, parser, rule engine 16 CommentsIn a comment on the rule engine project (ruleengine.codeplex.com) Damien wrote that he would need a like operator in the rule engine to make string compare with wildcards possible. So i added that feature to the rule engine. You now can write “Name like ‘mathi%'” and if the Name property of an object contains the string ‘mathias’ it would return that object. Here is a test that shows the cases that are now possible with the rule engine.
[TestMethod] public void SimpleExpressionLikeMethod() { Person person1 = new Person() { Name = "mathias", Age = 36, Children = 2, Married = true, Birthdate = new DateTime(1976, 05, 09), CancelBenefits = false, ReceiveBenefits = false }; Person person2 = new Person() { Name = "anna", Age = 32, Children = 2, Married = false, Birthdate = DateTime.Now, CancelBenefits = false, ReceiveBenefits = false }; Evaluator evaluator = new Evaluator(); var result1 = evaluator.Evaluate<Person>( " Name like 'math%' ", person1); Assert.AreEqual(result1, true); var result2 = evaluator.Evaluate<Person>( " Name like '?nn?' ", person2); Assert.AreEqual(result2, true); List<Person> list = new List<Person>() { person1, person2 }; foreach(var person in list) { var result = evaluator.Evaluate<Person>( " Name like 'mat%' || Name like 'a??a' ", person); if(result) { Debug.WriteLine(person.Name); Assert.AreEqual(result, true); } } }
As you see it there are two wildcard that work. The % wildcard can only be used at the end of the text, for example “Name like ‘mat%'”. The ? wildcard can be used in the at any possition, for example “Name like ‘math?ia?'”.
Reading a csv file into a DataTable with Linq
Posted: 14/11/2013 Filed under: .net, ADO.NET, c#, Linq | Tags: c#, csv, DataTable, linq 2 CommentsSome times ago i had the requirement to read a csv file into a DataTable and doint it the classical iterative way seems boring to me so i thought about the make all with one linq statement princip and tried to accomplish the whole processing with one linq statement. That are my results i want to share. I stated with the following statement.
public DataTable ImportFirstAdept(FileInfo fileInfo, char splitChar, Encoding encoding)
{
var plainfileName = Path.GetFileName(fileInfo.FullName);
DataTable dataTable = new DataTable(plainfileName);
var allRows = ((Func)(() => File.ReadAllLines(fileInfo.FullName, encoding)))();
allRows.
Select(str => str.Split(splitChar)).
First().
Select(columnHeader => { return new DataColumn(columnHeader.Trim()); }).
Foreach(column =>
{
dataTable.Columns.Add(column);
return column;
}).
ToList();
allRows.
Select(str => str.Split(splitChar)).
Skip(1).
Select(strArray =>
{
var strings = new List();
foreach (var s in strArray)
strings.Add(s.Trim());
return strings.ToArray();
}).
Select(st => dataTable.Rows.Add(st)).
ToList();
return dataTable;
}
The follwoing test shows how it works.
public void CsvToDataTableTest(string path)
{
DirectoryInfo directoryInfo = new DirectoryInfo(path);
CsvImport cvsImport = new CsvImport();
DataSet dataSet = new DataSet();
if (directoryInfo.Exists)
{
foreach (var file in directoryInfo.EnumerateFiles("*.csv"))
{
DataTable dataTable = cvsImport.ImportFirstAdept(file, '\t', Encoding.Default);
dataSet.Tables.Add(dataTable);
}
}
}
[TestMethod]
public void CsvToDataTablePrequelsTest()
{
CsvToDataTableTest(@"CsvToDataTableWithLinq\bin\Debug");
}
If we look at the ImportFirstAdept method it does not use one linq statement it uses two linq statements. So that was not sufficiently and i wrote some extension methodes to only use one Linq statement for the processing of the csv file.
public static class CsvImportExtension
{
public static void If(this IEnumerable source, Func ifFunc,
Action ifAction, Action elseAction)
{
var counter = 1;
List ifActions = new List();
List elseActions = new List();
foreach (var item in source)
{
if (ifFunc(item, counter))
{
ifActions.Add(item);
}
else
elseActions.Add(item);
counter++;
}
ifAction(ifActions.AsEnumerable());
elseAction(elseActions.AsEnumerable());
}
public static void If(this IEnumerable source, Func ifFunc,
Action ifAction, Action elseAction)
{
List ifActions = new List();
List elseActions = new List();
foreach (var item in source)
{
if (ifFunc(item))
{
ifActions.Add(item);
}
else
elseActions.Add(item);
}
ifAction(ifActions.AsEnumerable());
elseAction(elseActions.AsEnumerable());
}
public static IEnumerable Foreach(this IEnumerable source, Func foreachFunc)
{
foreach (var item in source)
{
yield return foreachFunc(item);
}
}
public static void Foreach(this IEnumerable source, Action foreachAction)
{
foreach (var item in source)
{
foreachAction(item);
}
}
}
That is the ImportSecondAdept method that uses the if and foreach extension methodes to only use one linq statement to process the csv file.
public DataTable ImportSecondAdept(FileInfo fileInfo, char splitChar, Encoding encoding)
{
var plainfileName = Path.GetFileName(fileInfo.FullName);
var dataTable = new DataTable(plainfileName);
((Func)(() => File.ReadAllLines(fileInfo.FullName, encoding)))().
Foreach(str => str.Split(splitChar)).
If((t, i) => i == 1,
t =>
{
t.First().
Foreach(columnHeader => { return new DataColumn(columnHeader.Trim()); }).
Foreach(column =>
{
dataTable.Columns.Add(column);
});
},
t =>
{
t.
Foreach(strArray =>
{
var strings = new List();
foreach (var s in strArray)
strings.Add(s.Trim());
return strings.ToArray();
}).
Foreach(str => dataTable.Rows.Add(str)).
ToList();
}
);
return dataTable;
}
That is the test to try it and the result of the second adept method.
public void CsvToDataTableTest(string path)
{
DirectoryInfo directoryInfo = new DirectoryInfo(path);
CsvImport cvsImport = new CsvImport();
DataSet dataSet = new DataSet();
if (directoryInfo.Exists)
{
foreach (var file in directoryInfo.EnumerateFiles("*.csv"))
{
DataTable dataTable = cvsImport.ImportSecondAdept(file, '\t', Encoding.Default);
dataSet.Tables.Add(dataTable);
}
}
}
[TestMethod]
public void CsvToDataTablePrequelsTest()
{
CsvToDataTableTest(@"CsvToDataTableWithLinq\bin\Debug");
}

So now it is only one linq statement and the one linq statement princip is suffused.
Building a rule engine in c# (part 6: extentions to the rule engine)
Posted: 11/11/2013 Filed under: .net, c#, rule engine | Tags: .net, c#, rule engine 6 CommentsWhen i started implementing the rule engine project (ruleengine.codeplex.com) it was thought as an example project. But i became some comments on the project that show that some people use the project productive and so i was asked to make some extensions to the rule engine. I am glad that someone uses my work an so i implemented the additional features. But the problem is that all that the description of that new features are spread over the comment sections of different posts. So in this post i want to summerice that features.
The first feature i was asked for by martin is that the rule engine has an is in and is not in operator. The FoundIn operator returns true if a person is in a list of given persons. The NotFoundIn operator gives back true if a person is not in a list of given persons. Here is the test i wrote to see if the operator works.
[TestMethod] public void SimpleRuleLoaderPersonEvaluateFoundInExpression() { Person person1 = new Person() { Name = "Mathias", Age = 36, Children = 2 }; Person person2 = new Person() { Name = "Anna", Age = 35, Children = 2 }; Person person3 = new Person() { Name = "Emil", Age = 4, Children = 0 }; List<Person> persons = new List<Person>(); persons.Add(person1); persons.Add(person2); RuleEngine.RuleEngine ruleEngine = new RuleEngine.RuleEngine(); var ruleFunc = ruleEngine.CompileRule<Person>("Name", Operator.FoundIn, persons); var result = ruleFunc(person1); Rule<Person> rule = new Rule<Person>("Name", Operator.NotFoundIn, persons); var ruleFuncRule = ruleEngine.CompileRule<Person>(rule); var ruleFuncRuleResult = ruleFuncRule(person3); Assert.AreEqual(result, true); Assert.AreEqual(ruleFuncRuleResult, false); }
To implement that operator i had build a expression tree that is more complex that the simple one for Equal, Unequal, SmallerThen etc. Here is the code that builds the expression tree to check if a person with a given attribute is in a list of persons.
public Tuple<Expression, ParameterExpression> BuildExpression<T>(string propertyName, Operator ruleOperator, ParameterExpression parameterExpression, List<T> values) { ParameterExpression listExpression = Expression.Parameter(typeof(List<T>)); ParameterExpression counterExpression = Expression.Parameter(typeof(int)); ParameterExpression toExpression = Expression.Parameter(typeof(int)); ParameterExpression arrayExpression = Expression.Parameter(typeof(T[])); ParameterExpression valueExpression = Expression.Parameter(typeof(T)); ParameterExpression checkExpression = Expression.Parameter(typeof(T)); ParameterExpression returnExpression = Expression.Parameter(typeof(bool)); MemberExpression memberExpression = MemberExpression.Property(parameterExpression, propertyName); Expression expression = memberExpression.Expression; var type = memberExpression.Type; ParameterExpression propertyExpression = Expression.Parameter(type); ParameterExpression localPropertyExpression = Expression.Parameter(type); LabelTarget breakLabel = Expression.Label(); PropertyInfo result = typeof(List<T>).GetProperty("Count"); MethodInfo toArray = typeof(List<T>).GetMethod("ToArray"); var toArrayName = toArray.Name; MethodInfo getGetMethod = result.GetGetMethod(); ConstantExpression constantExpression = Expression.Constant(true); if (ruleOperator == Operator.NotFoundIn) { constantExpression = Expression.Constant(false); } Expression loop = Expression.Block( new ParameterExpression[] { toExpression, arrayExpression, valueExpression, counterExpression, returnExpression, propertyExpression, localPropertyExpression, listExpression }, Expression.Assign(listExpression, Expression.Constant(values)), Expression.Assign(toExpression, Expression.Call(listExpression, getGetMethod)), Expression.Assign(arrayExpression, Expression.Call(listExpression, toArray)), Expression.Assign(propertyExpression, MemberExpression.Property(checkExpression, propertyName)), Expression.Loop( Expression.IfThenElse( Expression.LessThan(counterExpression, toExpression), Expression.Block( Expression.Assign(valueExpression, Expression.ArrayAccess(arrayExpression, counterExpression)), Expression.Assign(localPropertyExpression, Expression.Property(valueExpression, propertyName)), Expression.IfThen( Expression.Equal(propertyExpression, localPropertyExpression), Expression.Block(Expression.Assign(returnExpression, constantExpression), Expression.Break(breakLabel))), Expression.Assign( Expression.ArrayAccess(arrayExpression, counterExpression), checkExpression), Expression.PostIncrementAssign(counterExpression)), Expression.Break(breakLabel) ), breakLabel ), Expression.And(returnExpression, constantExpression) ); return new Tuple<Expression, ParameterExpression>(Expression.Block(loop), checkExpression); }
This code builds a loop that enumerates a list of objects and checks a specified property (localPropertyExpression specified by propertyName) has the same value as the propertyExpression. If the values are the same the returnExpression is set to true. (if it is the NotFoundIn operator it is set to false). The CompileRule call looks the following:
public Func<T, bool> CompileRule<T>(string propertyName, Operator ruleOperator, List<T> values) { ExpressionBuilder expressionBuilder = new ExpressionBuilder(); var param = Expression.Parameter(typeof(T)); Tuple<Expression, ParameterExpression> expression = expressionBuilder.BuildExpression<T>(propertyName, ruleOperator, param, values); Func<T, bool> compiledExpression = Expression.Lambda<Func<T, bool>>( expression.Item1, expression.Item2).Compile(); return compiledExpression; }
The differnece to all the other CompileRule methodes is that it takes a list of values. That list of values becomes iterated in the expression tree.
The second feature i was asked for by Mike is that he needed to call a method at the person object if a specific property of the person has a specific value. The problem was that he needed that in the expression evaluator string. The following code shows what he needed.
var tuple = evaluator.Evaluate<Person>( " (Age < 10) then SetCanReceiveBenefits(true) else SetCancelBenefits(true) ");
To check if the evaluation works correct i have added two methodes (SetCanReceiveBenefits and SetCancelBenefits) to the person object.
public class Person { public string Name { get; set; } public int Age { get; set; } public int Children { get; set; } public bool Married { get; set; } public DateTime Birthdate { get; set; } public Adresse Adresse_ { get; set; } public bool ReceiveBenefits { get; set; } public bool CancelBenefits { get; set; } public void SetCanReceiveBenefits(bool receiveBenefits) { ReceiveBenefits = receiveBenefits; } public void SetCancelBenefits(bool cancelBenefits) { CancelBenefits = cancelBenefits; } private List<Adresse> adresses = new List<Adresse>(); public List<Adresse> Adresses_ { get { return adresses; } set { adresses = value; } } }
After that i had to change the lexer and the parser of the evaluation evaluator to handle the then and else keyword. Here is the complete test that shows how to use the then and else keyword.
[TestMethod]
public void SimpleExpressionEvaluatorWithThenMethod()
{
Person person1 = new Person()
{
Name = "Mathias",
Age = 36,
Children = 2,
Married = true,
Birthdate = new DateTime(1976, 5, 9),
CancelBenefits = false,
ReceiveBenefits = false
};
Evaluator evaluator = new Evaluator();
bool result = evaluator.Evaluate(
" (Age > 10) then SetCanReceiveBenefits(true) ", person1);
Assert.AreEqual(person1.ReceiveBenefits, true);
}
Here is the test that shows how the else keyword works.
[TestMethod]
public void SimpleExpressionPreEvaluatorWithThenAndElseMethod()
{
Person person1 = new Person()
{
Name = "Mathias",
Age = 36,
Children = 2,
Married = true,
Birthdate = new DateTime(1976, 5, 9),
CancelBenefits = false,
ReceiveBenefits = false
};
Evaluator evaluator = new Evaluator();
bool result = evaluator.Evaluate(
" (Age < 10) then SetCanReceiveBenefits(true) else SetCancelBenefits(true) ", person1);
Assert.AreEqual(person1.CancelBenefits, true);
}
Mike also wrote that he needs the rule engine to work with many objects and asked if it is possible that the rule engine could preprocess the evaluation of the expression. So i splitted the evaluation process and added the PreEvalute method to preprocess the evaluation of the evaluation string and the building of the symbol table. The ExecuteEvaluate method takes the prepocessed abstract syntax tree and the symbol table and does only the evaluation with the given object. Her is a test that shows that preprocessing step.
[TestMethod]
public void SimpleExpressionPreEvaluatorWithThenElseMethod()
{
Person person1 = new Person()
{
Name = "Mathias",
Age = 36,
Children = 2,
Married = true,
Birthdate = new DateTime(1976, 5, 9),
CancelBenefits = false,
ReceiveBenefits = false
};
Person person2 = new Person()
{
Name = "Anna",
Age = 32,
Children = 2,
Married = false,
Birthdate = new DateTime(2002, 2, 2),
CancelBenefits = false,
ReceiveBenefits = false
};
Evaluator evaluator = new Evaluator();
var tuple = evaluator.PreEvaluate(
" (Age < 10) then SetCanReceiveBenefits(true) else SetCancelBenefits(true) ");
evaluator.ExecuteEvaluate(tuple, person1);
evaluator.ExecuteEvaluate(tuple, person2);
Assert.AreEqual(person1.CancelBenefits, true);
Assert.AreEqual(person2.CancelBenefits, true);
}
If you use rule engine in a real project that could save a lot of time because the evaluation needs some time and repeats over and over again if you use the normal evaluate method.
The third feature i was asked for by Damian, and he needed to check if a specific property is null. So i implemented the is null operator. The problem is that in c# value types like int can not take null so this operator works only correct with strings. The following test shows how the is null operator works.
[TestMethod]
public void SimpleExpressionStringIsNullMethod()
{
Person person2 = new Person()
{
Name = null,
Age = 32,
Children = 2,
Married = false,
Birthdate = new DateTime(2002, 2, 2),
CancelBenefits = false,
ReceiveBenefits = false
};
Evaluator evaluator = new Evaluator();
var result = evaluator.Evaluate(
" Name is null ", person2);
Assert.AreEqual(result, true);
}
So if you want to use the rule engine in real world projects i hope that helps to check all rules you have to check.
Distinct a DataTable with c#
Posted: 07/09/2013 Filed under: .net, ADO.NET, c#, Linq | Tags: .net, ADO.NET, c#, DataTable, DataView, Distinct, IEqualityComparer Leave a commentToday i want to write about the different possibilities to distinct the data in a DataTable. I had that problem some times ago and searched for a good solution. I found some different solutions and in that post i will show them. First i want to show the test i wrote to test the distinct of the DataTable and the data stored in the DataTable.
[TestMethod] public void Distinct() { DataTable dataTable = new DataTable("Distinct"); var oldPK = new DataColumn() { ColumnName = "PK", DataType = typeof(int) }; dataTable.Columns.Add(oldPK); var secondPK = new DataColumn() { ColumnName = "secondPK", DataType = typeof(int) }; dataTable.Columns.Add(secondPK); dataTable.Columns.Add(new DataColumn() { ColumnName = "firstname", DataType = typeof(string) }); dataTable.Columns.Add(new DataColumn() { ColumnName = "secondname", DataType = typeof(string) }); dataTable.Columns.Add(new DataColumn() { ColumnName = "socialSecurityNumber", DataType = typeof(int) }); dataTable.PrimaryKey = new DataColumn[] { oldPK, secondPK }; foreach (var number in Enumerable.Range(1, 3)) { DataRow dataRow = dataTable.NewRow(); dataRow["PK"] = number; dataRow["secondPK"] = number + 1; dataRow["firstname"] = "mathias"; dataRow["secondname"] = "schober"; dataRow["socialSecurityNumber"] = 4040; dataTable.Rows.Add(dataRow); } foreach (var number in Enumerable.Range(4, 2)) { DataRow dataRow = dataTable.NewRow(); dataRow["PK"] = number; dataRow["secondPK"] = number + 1; dataRow["firstname"] = "anna"; dataRow["secondname"] = "schober"; dataRow["socialSecurityNumber"] = 5050; dataTable.Rows.Add(dataRow); } var newDataTable = dataTable.Distinct("socialSecurityNumber"); var newDataViewDataTable = dataTable.DistinctDataView("socialSecurityNumber"); var newEqualityCompareDataTable = dataTable.DistinctEqualityCompare("socialSecurityNumber"); var newGenericEqualityCompareDataTable = dataTable.DistinctGenericEqualityCompare("socialSecurityNumber"); }

As we see i wrote four different methods to distinct the DataTable. The first on Distinct is the classical way. I create a new DataTable, take the original DataTable, enumerate all rows and check if the value of the overtaken column (in the test i use socialSecurityNumber) is already in the new DataTable. Then i set the primary key of the new DataTable and reorder the columns to bring the primary key (overtaken column) to the first position. Here you see the code to do so.
public static class Distincting { public static DataTable Distinct(this DataTable dataTable, string columName) { DataColumn[] dataColumns = dataTable.PrimaryKey; if (dataColumns.Length >= 1) { foreach (DataColumn primaryKey in dataColumns) { if (primaryKey.ColumnName == columName) { return dataTable; } } } return RebuildDataTable(dataTable, columName); } private static DataTable RebuildDataTable(DataTable dataTable, string columName) { DataTable newDataTable = dataTable.Clone(); DataColumn newDataColumn = newDataTable.Columns[columName]; newDataTable.PrimaryKey = new DataColumn[] { newDataColumn }; newDataTable.Columns[columName].SetOrdinal(0); dataTable.Rows.Foreach(dataRow => { object pk = dataRow[columName]; if (newDataTable.Rows.Find(pk) == null) { newDataTable.ImportRow(dataRow); } }); ReorderPrimaryKey(dataTable, newDataTable); return newDataTable; } private static void ReorderPrimaryKey(DataTable dataTable, DataTable newDataTable) { int maxOrdinal = 0; foreach (DataColumn column in newDataTable.Columns) { if (column.Ordinal > maxOrdinal) maxOrdinal = column.Ordinal; } DataColumn[] dataColumns = dataTable.PrimaryKey; if (dataColumns.Length >= 1) { foreach (DataColumn primaryKey in dataColumns) { newDataTable.Columns[primaryKey.ColumnName]. SetOrdinal(maxOrdinal); } } } }
public static class ForEachEnumeration { public static void Foreach(this DataRowCollection dataRows, Action action) { foreach(T dataRow in dataRows) { action(dataRow); } } }
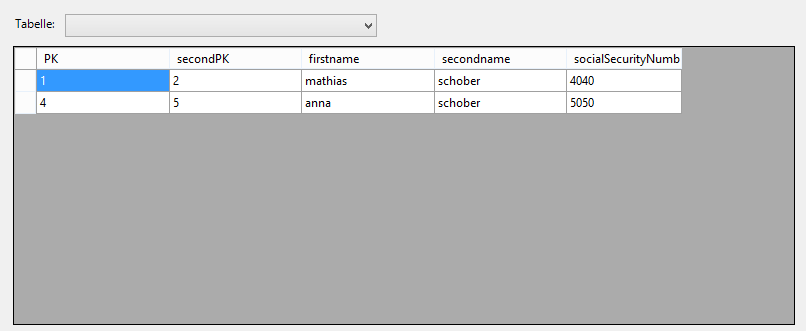
After distincting with the social sercurity number we have the following DataTable.

The second possibility to distinct a DataTable is using the ToTable method of the DataView. In the next code part you can see how that works.
public static DataTable DistinctDataView(this DataTable dataTable, string columName) { DataView view = new DataView(dataTable); return view.ToTable(true, new string[] { columName }); }
That is the resulting DataTable. As we see it contains only the social security number. The other columns are gone.

After the classic version and the DataView version it is also possible to solve the problem with the linq Distinct Extension method.
public static DataTable DistinctEqualityCompare(this DataTable dataTable, string columName) { DataRowEqaulityComparer dataRowEqualityComparer = new DataRowEqaulityComparer(columName); return dataTable.AsEnumerable(). Distinct(dataRowEqualityComparer).CopyToDataTable(); }
To accomplish that we need a EqualityComparer.
public class DataRowEqualityComparer : IEqualityComparer { private string distinctColumnName; public DataRowEqualityComparer(string distinctColumnName) { this.distinctColumnName = distinctColumnName; } public bool Equals(DataRow x, DataRow y) { if (x.Field<object>(distinctColumnName). Equals(y.Field<object>(distinctColumnName))) { return true; } return false; } public int GetHashCode(DataRow obj) { return obj.Field<object>(distinctColumnName).GetHashCode(); } }
Or we could also use a Generic EqualityComparer. (implementing a generic IEqualityComparer and IComparer class)
public static DataTable DistinctGenericEqualityCompare(this DataTable dataTable, string columName) { EqualityComparer dataRowEqualityComparer = new EqualityComparer( (x, y) => x.Field<object>(columName).Equals(y.Field<object>(columName)), x => x.Field<object>(columName).GetHashCode() ); return dataTable.AsEnumerable(). Distinct(dataRowEqualityComparer).CopyToDataTable(); }
public class EqualityComparer : IEqualityComparer { private Func<T, T, bool> equalsFunction; private Func<T, int> getHashCodeFunction; public EqualityComparer(Func<T, T, bool> equalsFunction) { this.equalsFunction = equalsFunction; } public EqualityComparer(Func<T, T, bool> equalsFunction, Func<T, int> getHashCodeFunction) : this(equalsFunction) { this.getHashCodeFunction = getHashCodeFunction; } public bool Equals(T a, T b) { return equalsFunction(a, b); } public int GetHashCode(T obj) { if (getHashCodeFunction == null) return obj.GetHashCode(); return getHashCodeFunction(obj); } }
That is the resulting DataTable.
That are all possibilities i could think of to distinct a DataTable.
building a simple spam filter with naive bayes classifier and c#
Posted: 25/05/2013 Filed under: .net, Algorithm, c#, Maschine learning, Parsing | Tags: c#, maschine learning, naive bayes classifiers, spam filter Leave a commentHave you also often wondered how a filter works? I have and last month I got a book in my fingers that deals with machine learning. In that book there is a chapter about naive bayer classifier, and that naive bayer classifiers are used to implement spam filtering. All programming examples in that book are in python and I do not speak python, so i calculated the naive bayer classifier myself, wrote a c# program and put it on codeplex (naivebayes.codeplex.com). I made the application only do demonstrate the principle of spam filtering, it is not for practical use. To understand how naive bayes classifiers work the best example is the cookie problem. Lets assume we have two bowls with cookies in it.
Bowl 1: 5 chocolate cookies and 35 vanilla cookies
Bowl 2: 20 chocolate cookies and 20 vanilla cookies
Now we take one cookie (it is a vanilla cookie) and we have 50 percent chance that we take it from bowl 1 or from bowl2. Now we have two hypothesis:
1. It is from bowl 1
H1 = 1/2
2. It is from bowl 2
H2 = 1/2
That means that we have a 50 to 50 chance to pick from bowl 1 or from bowl 2
P(h1) = P(h2) = 1/2
After defining our hypothesis and taking one vanilla cookie, now we have one evidence, and we can calculate the probability that we took it from bowl 1 or bowl 2. So now we can define the hypothesis under the evidence that we took a vanilla cookie.
P(E/h1) = 35/40 (because we took one cookie that is vanilla the chance is 35/40) P(E/h2) = 20/40 = 1/2 (because we took one cookie that is vanilla but the chance is 1/2)
P(E/h1) is 35/40 because we have 35 vanilla cookies out of 40
P(E/h2) is 1/2 because we have 20 vanilla cookies out of 40
At this point we need bayes theorem:
P(h1/E) = P(h1) * P(E/h1) / P(E)
Bayes theorem says that you can calculate the evidence under the hypothesis one P(h1/E) with multiplying the P(h1) with the calculated evidence under the hypothesis P(E/h1) divided by a base P(E). To calculate P(h1/E) that is the value that tells us how big the chance is that our hypothesis one is correct. What we need to calculate that value is P(E). In this case it is very easy to find. Is is the sum of all vanilla cookies divided by the sum of all cookies.
P(E) = sum(vanilla cookies) / sum(all cookies) -> 55 / 80
So now we have all values we need for bayes theorem.
P(h1/E) = P(h1) * P(E/h1) / P(E) -> P(h1/E) = (1/2 * 35/40) / 55/80 = 0.5 * 0,875 / 0,6875 = 0.6363636363 = 63.6 %
That means after taking one vanilla cookie we can say that the chance that we take cookies from bowl 1 is 63.6 percent.
So that’s it with the cookie problem but how can us help that by implementing a spam filter? We can calculate the possibility if a mail we get is spam or not spam with the same formula, with bayes theorem.
But instead of cookies we use mails we have classified as spam mails or as not spam mails. So if we get a new mail, we take every word and calculate a value Q. If Q is greater than 1 the word comes more likely from a spam mail, if Q is smaller than 1 the word comes more likely not from a spam mail. So the rule will be
Q > 1 = spam
Q < 0 = not spam
Now we will calculate Q for every word w.
Our hypothesis h1 and h2 are:
H1 = HSpam = 1/2
H2 = HNotSpam = 1/2
So we have again have a 50 to 50 chance
P(h1) = P(h2) = 1/2
Now we need some evidence data, in our case we have 10 spam mails and 10 not spam mails. That mails will give us the evidence we need to decide if the word comes from a spam mail or not. So now we take one word we have in the mail we want to check. Lets say the word is mother. We look in the spam mails and we find it one time. Then we look in the not spam mails and we find it five times. With that information we can calculate P(E/h1) and P(E/h2):
P(E/h1) = 1 / 10 (one mail out of ten)
P(E/h2) = 5 / 10 (five mails out of ten)
Now we use bayes theorem to calculate P(h1/E) and P(h2/E).
P(h1/E) = P(h1) * P(E/h1) / P(E)
P(h2/E) = P(h2) * P(E/h2) / P(E)
Normally we have to figure out what P(E) is but in this case P(E) refers only to the actual mail that means it is one and we can remove it. Here is the calculation:
P(h1/E) = 1/2 * 1/10 / 1 = 1/20
P(h2/E) = 1/2 * 5/10 / 1 = 5/20
So we have two values that tell us how big the chance is that a mail is a spam mail or not. (based on the spam and not spam mails we already got)
Now we calculate Q and check if it is greater or smaller that 1.
Q = P(h1/E) / P(h2/E) = 1/20 / 5/20 = 1/5 = 0.2
Q is smaller that one that means that the word mother occurs more often in one of our not spam mails. To check all the text in a mail we only have to calculate Q for every word sum all Q values up and divide it through the number of all words in the email.
Q overall = sum(calculate Q for every word w) / count(every word w)
Q overall > 1 = spam
Q overall < 0 = not spam
Now all we have to do is to implement a program that takes the emails and checks a given email for spam. To check if the program does what it should do, i implemented two tests that check phrases. The NaiveBayersSpamTrueTest method uses phrases from spam mails and the NaiveBayersNotSpamFalseTest method uses phrases from not spam mails.
That is the spam true test.
[TestMethod] public void NaiveBayersSpamTrueTest() { NaiveBayes.NaiveBayes naiveBayes = new NaiveBayes.NaiveBayes(); var result = naiveBayes.CheckEmail("Buy Cheap cialis Online"); Assert.AreEqual(true, result); result = naiveBayes.CheckEmail("Enlarge Your Penis"); Assert.AreEqual(true, result); result = naiveBayes.CheckEmail("accept VISA, MasterCard"); Assert.AreEqual(true, result); }
That is the spam not true test.
[TestMethod] public void NaiveBayersNotSpamFalseTest() { NaiveBayes.NaiveBayes naiveBayes = new NaiveBayes.NaiveBayes(); var result = naiveBayes.CheckEmail("Sincerely Mathias"); Assert.AreEqual(false, result); result = naiveBayes.CheckEmail("Dear Graduates"); Assert.AreEqual(false, result); result = naiveBayes.CheckEmail("Thanks in advance for your support"); Assert.AreEqual(false, result); result = naiveBayes.CheckEmail("for it with my Mastercard"); Assert.AreEqual(false, result); }
Now that we have the tests we start with the part that reads the evidence data. What i did is, i took 10 normal mails and 10 spam mails from my inbox and my spam folder and made 10 text files out of them. Then i implemented a method that read all the data from the text files. (the text files with the text from the spam mails and not spam mails are at the naivebayes.codeplex.com project)
public class EmailReader { public List<string> Read(string pathToFiles) { List<string> list = new List<string>(); DirectoryInfo currentdirectoryInfo = new DirectoryInfo(Environment.CurrentDirectory); DirectoryInfo parent = currentdirectoryInfo.Parent.Parent.Parent; DirectoryInfo directoryInfo = new DirectoryInfo(parent.FullName + @"\NaiveBayes" + pathToFiles); if (directoryInfo.Exists) { foreach (var file in directoryInfo.EnumerateFiles()) { var text = String.Empty; using(FileStream filestream = file.OpenRead()) { System.IO.StreamReader streamReader = new System.IO.StreamReader(filestream); text = streamReader.ReadToEnd(); } list.Add(text); } } return list; } }
The methode Read is called two times, one time for the spam mails and one time for the not spam mails. After reading the text from the text files i need a class that parses all words from the text into a dictionary and count how often a word occurs. So that parser tells me how often a word occurs in all my spam mails and in all my not spam mails. So for simplicity the parser takes the text of every mail and splits it into word by using the string.Split(‘ ‘) method, that means every times a blank occurs a new word starts.
public class Parser { private Dictionary<string, int> wordCounter = new Dictionary<string,int>(); public Dictionary<string, int> WordCounter { get { return wordCounter; } set { wordCounter = value; } } public void Parse(string textToParse) { var stringArray = textToParse.Split(' '); foreach (var str in stringArray) { if (wordCounter.ContainsKey(str.ToLower())) { wordCounter[str.ToLower()] += 1; } else { wordCounter.Add(str.ToLower(), 1); } } } }
Now all the groundwork is done. What we need now is the method that calculates Q for every word and calculates out of all Q values of all words of our email, if it is spam or not spam. In the constructor of the NaiveBayes class the mails are read and saved in the spamMails and notSpamMails variable. The CheckMail method is the starting point of the calculation. First it parses the spamMails and the notSpamMails string and fills two dictionaries with the spam and the not spam mails words. Then the CheckIfSpam method is called that splits the mail text in words and calls for every word the CalculateQ method. Then it sums up all q values and divided it by the count of all tested words. If the calculated value is bigger one it returns true that means spam if not it returns false that means no spam. In the CalculateQ method we calculate Q with the bayes theorem.
P(h1/E) = P(h1) * P(E/h1) / P(E)
We calculate Ph1e by dividing wordCountSpam by countSpamMails and Ph2e by dividing wordCountNotSpam with countNotSpamMails. Then we divide Ph1e by Ph2e and the result is q.
public class NaiveBayes { private List<string> spamMails; private List<string> notSpamMails; private int countSpamMails; private int countNotSpamMails; public NaiveBayes() { EmailReader emailReader = new EmailReader(); spamMails = emailReader.Read(@"\Mails\Spam\"); notSpamMails = emailReader.Read(@"\Mails\NotSpam\"); countSpamMails = spamMails.Count(); countNotSpamMails = notSpamMails.Count(); } public bool CheckEmail(string text) { Parser parser = new Parser(); foreach(var spamMail in spamMails) { parser.Parse(spamMail); } var spamWords = parser.WordCounter; parser = new Parser(); foreach (var notSpamMail in notSpamMails) { parser.Parse(notSpamMail); } var notSpamWords = parser.WordCounter; return CheckIfSpam(text, countSpamMails, spamWords, countNotSpamMails, notSpamWords); } private bool CheckIfSpam(string text, int countSpamMails, Dictionary<string,int> spamWordList, int countNotSpamMails, Dictionary<string,int> notSpamWordList) { var stringArray = text.Split(' '); var sumQ = 0.0; var wordCounter = 0; foreach (var item in stringArray) { var q = CalculateQ(item.ToLower(), countSpamMails, spamWordList, countNotSpamMails, notSpamWordList); sumQ += q; wordCounter++; } if (sumQ / wordCounter > 1) { return true; } else { return false; } } private double CalculateQ(string word, int countSpamMails, Dictionary<string,int> spamWordList, int countNotSpamMails, Dictionary<string,int> notSpamWordList) { double wordCountSpam = 1; if (spamWordList.ContainsKey(word)) { wordCountSpam = spamWordList[word]; } double Ph1e = 0.5 * wordCountSpam / countSpamMails; double wordCountNotSpam = 1; if (notSpamWordList.ContainsKey(word)) { wordCountNotSpam = notSpamWordList[word]; } double Ph2e = 0.5 * wordCountNotSpam / countNotSpamMails; double q = Ph1e / Ph2e; return q; } }
So that’s it, if we now give the CheckEmail method a phrase (e.g. “Thanks in advance for your support”) it recognises that this is not from a spam mail. The complete source code including the text from spam and not spam mails is in the naivebayes.codeplex.com project. If you need more information about naive bayes classification i would recommend the open book Think Stats: Probability and Statistics for Programmers. I have to say that I really enjoyed implementing the naive bayes classifier, because i always wanted to know how a spam filter works and it is surprising how good it works.
little or big endian in c#
Posted: 24/05/2013 Filed under: .net, Algorithm, c# | Tags: big endian, c#, endianness, little endian Leave a commentIf you want to check the endianess of your operating system in c# you have two possibilities, a safe and a unsafe way. But first of all i want to explain what endianess is and what big and little endian means. If you have an Int32 value in c#, that Int32 is saved in 4 bytes. But the question is which part of the Int32 is saved in which byte with which address. If the system is using little endian (like Windows does) the last byte (=least significant byte) is saved in the lowest address. That means if you have the hex value 0A0B0C0D and you have the Int32 has the address 00000001, the bytes are saved in the following order:
0D at address 00000001
0C at address 00000002
0B at address 00000003
0A at address 00000004
The following images shows the insertion order:

If the system has big endian order the last byte (=least significant byte) is saved in the highest address. That means the Int32 value 0A0B0C0D with the address 00000001 the bytes are inserted the following way:
0A at address 00000001
0B at address 00000002
0C at address 00000003
0D at address 00000004
The following image shows the insertion order:

Now if we want to check if the system uses big or little endian in c# there is a very easy way, you can use the BitConverter class that has an IsLittleEndian property.
if(BitConverter.IsLittleEndian) return "Little Endian";
If you want to implement the check yourself the simplest method is the following one:
public enum BigLittleEndianEnum { Big, Little } public BigLittleEndianEnum TestSystemIsBigOrLittleEndianSafe() { Int32 intValue = 0x0001; byte[] bytes = BitConverter.GetBytes(intValue); var safeBigLittleEndian = (bytes[0] == 1) ? BigLittleEndianEnum.Little : BigLittleEndianEnum.Big; return safeBigLittleEndian; }
What we do is we take the Int32 type intValue and assign 1 to it. Then we use the BitConverter class to generate a byte array out of that Int32 value. If the zero byte of the array (byte[0]) is one the we know that the system uses little endian because the 1 is in the lowest address (byte[0]).
If you search for check little or big endian in google you often find the c/c++ solution. In c# you have to use the unsafe keyword, because you need pointer syntax to implement the c/c++ solution.
public BigLittleEndianEnum TestSystemIsBigOrLittleEndianUnsafe() { Int32 intValue = 0x0001; unsafe { Int32* intValueAddress = &intValue; byte* byteValueAddress = (byte*) intValueAddress; byte byteValue = *byteValueAddress; var unsafeBigLittleEndian = (byteValue == 1) ? BigLittleEndianEnum.Little : BigLittleEndianEnum.Big; return unsafeBigLittleEndian; } }
Here we use a pointer of the Int32 intValue and cast it to a byte pointer. That byte pointer points on the lowest address (byte[0]) of the Int32 value and you can check if the value the pointer points on is zero or one, if it is one its little endian. A real c/c++ programmer would write that whole method in two lines:
public BigLittleEndianEnum TestSystemIsBigOrLittleEndianUnsafe() { Int32 intValue = 0x0001; return *((byte*) &intValue) == 1 ? BigLittleEndianEnum.Little : BigLittleEndianEnum.Big; }
For a more detailed explanation please look at the wickipedia article about Endianess.
creating generic object or generic method with reflection.
Posted: 06/04/2013 Filed under: .net, c# | Tags: c#, generic method, generic object, generics, reflection Leave a commentSome times i am in a situation that i needed to create a generic Type or a generic Method with a changing type at runtime. I will start with the generation of a generic method. Lets asume i have a method ConvertValue defined in a class Converter:
public class Converter { public TResult ConvertValue<TResult>(int value) { TResult resultValue = (TResult)Convert.ChangeType(value, typeof(TResult)); return resultValue; } } var intValue = 10; Converter converter = new Converter(); double doubleValue = converter.ConvertValue(intValue);
As we see that method converts an int value to a generic type, in our case in a double. But what is if we dont know the type we want to convert in the intValue at compile type. What if the type is choosen at runtime. Then we need the MakeGenericMethod method from the System.Reflection namespace. That call builds a generic method and then we can invoke that method with the correct generic type.
public class CreateGenericTypeAndMethod { public static object MakeGenericMethod(object obj, string methodName, Type innerType, params object[] args) { MethodInfo method = obj.GetType().GetMethod(methodName, BindingFlags.Public | BindingFlags.NonPublic | BindingFlags.Instance | BindingFlags.Static); MethodInfo generic = method.MakeGenericMethod(innerType); return generic.Invoke(obj, args); } } var intValue = 10; Type type = typeof(double); object obj = MakeGenericMethod(new Converter(), "ConvertValue", type, 10); // obj is now from type double and has the value 10.0 var str = String.Format("{0:0.0}",((double)obj)); Console.WriteLine("obj has the type {0} and the value {1}", obj.GetType(), str);
After the MakeGenericMethod call the obj object is now from type double and has the value 10.0 .

But what is if you want to generate a class with a generic type T. In the next example i show how to generate a Stack of type T. The type T is not known at compile type but at runtime.
public class Stack<T> { private List<T> list = new List<T>(); public void Push(T value) { list.Add(value); } public T Pop() { if (list.Count > 0) { T value = list[list.Count - 1]; list.RemoveAt(list.Count - 1); return value; } return default(T); } } public class CreateGenericTypeAndMethod { public static object MakeGenericType(Type generic, Type innerType, params object[] args) { Type specificType = generic.MakeGenericType(new Type[] { innerType }); return Activator.CreateInstance(specificType, args); } }
Type type = typeof(double); object stack = CreateGenericTypeAndMethod.MakeGenericType (typeof(Stack<>), type, new object[] { });
Here i generate a Stack for double values.

I call the MakeGenericType method with the type of the object (Stack) and the type of the generic type (double). In the MakeGenericType method i generate the generic type of the Stack (Stack). For that generation i use the MakeGenericType method of the Type class. With that type i instanciate the object by calling Activator.CreateInstance. That is all i have to do to create the Stack.
Here is the complete implementation of the CreateGenericTypeAndMethod class. There are two overloads for generic type generation and generic methode generation with one generic parameter or multible generic parameters.
public class CreateGenericTypeAndMethod { public static object MakeGenericType(Type generic, Type innerType, params object[] args) { Type specificType = generic.MakeGenericType(new Type[] { innerType }); return Activator.CreateInstance(specificType, args); } public static object MakeGenericType(Type generic, Type[] innerTypes, params object[] args) { Type specificType = generic.MakeGenericType(innerTypes); return Activator.CreateInstance(specificType, args); } public static object MakeGenericMethod(object obj, string methodName, Type innerType, params object[] args) { MethodInfo method = obj.GetType().GetMethod(methodName, BindingFlags.Public | BindingFlags.NonPublic | BindingFlags.Instance | BindingFlags.Static); MethodInfo generic = method.MakeGenericMethod(innerType); return generic.Invoke(obj, args); } public static object MakeGenericMethod(object obj, string methodName, Type[] innerTypes, params object[] args) { MethodInfo method = obj.GetType().GetMethod(methodName, BindingFlags.Public | BindingFlags.NonPublic | BindingFlags.Instance | BindingFlags.Static); MethodInfo generic = method.MakeGenericMethod(innerTypes); return generic.Invoke(obj, args); } }
